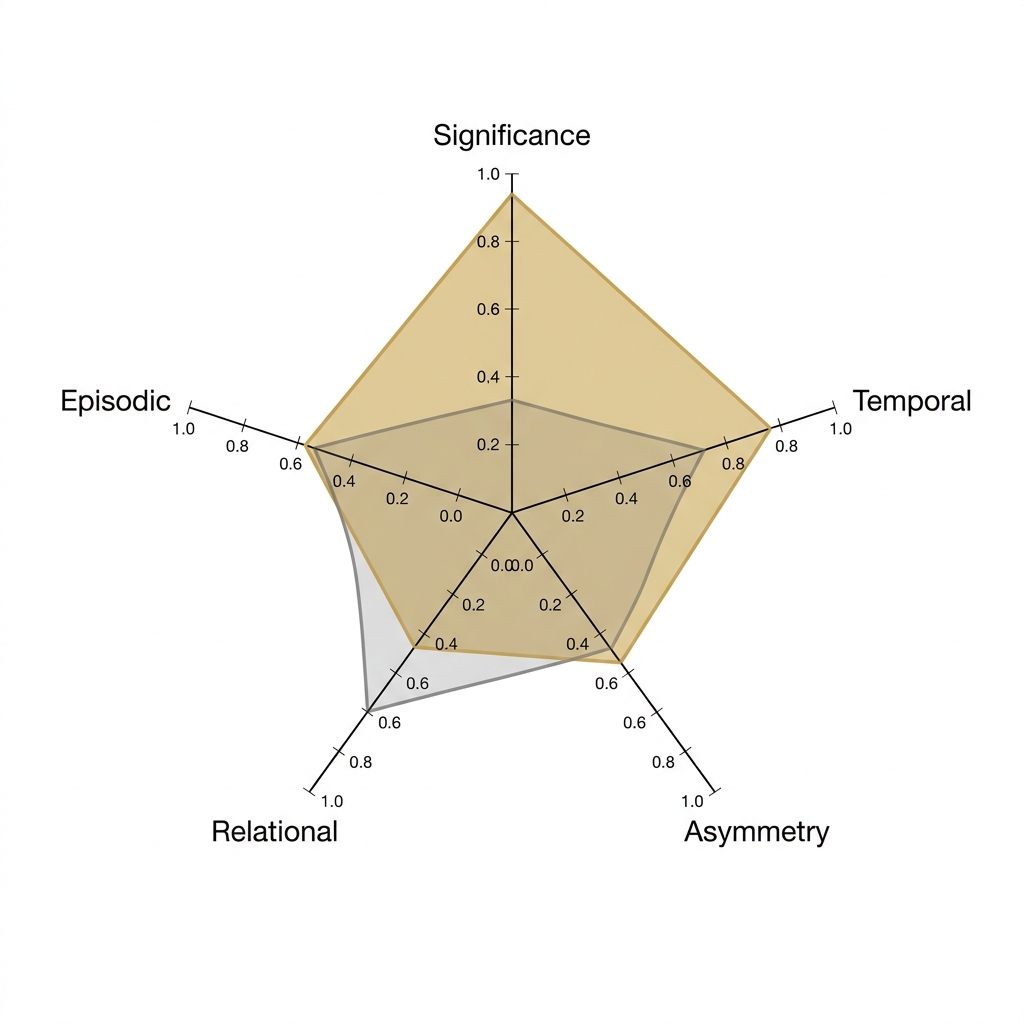
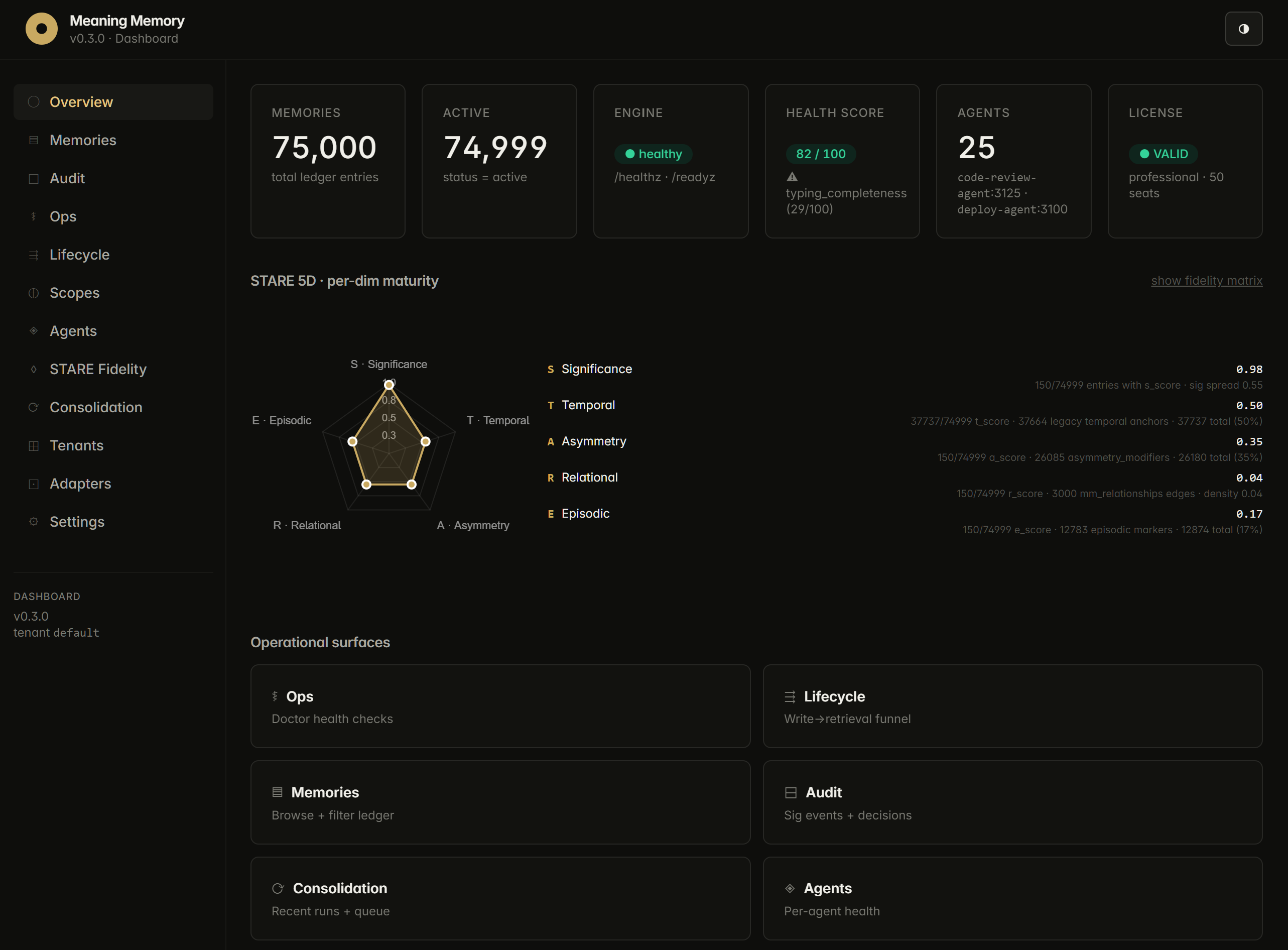
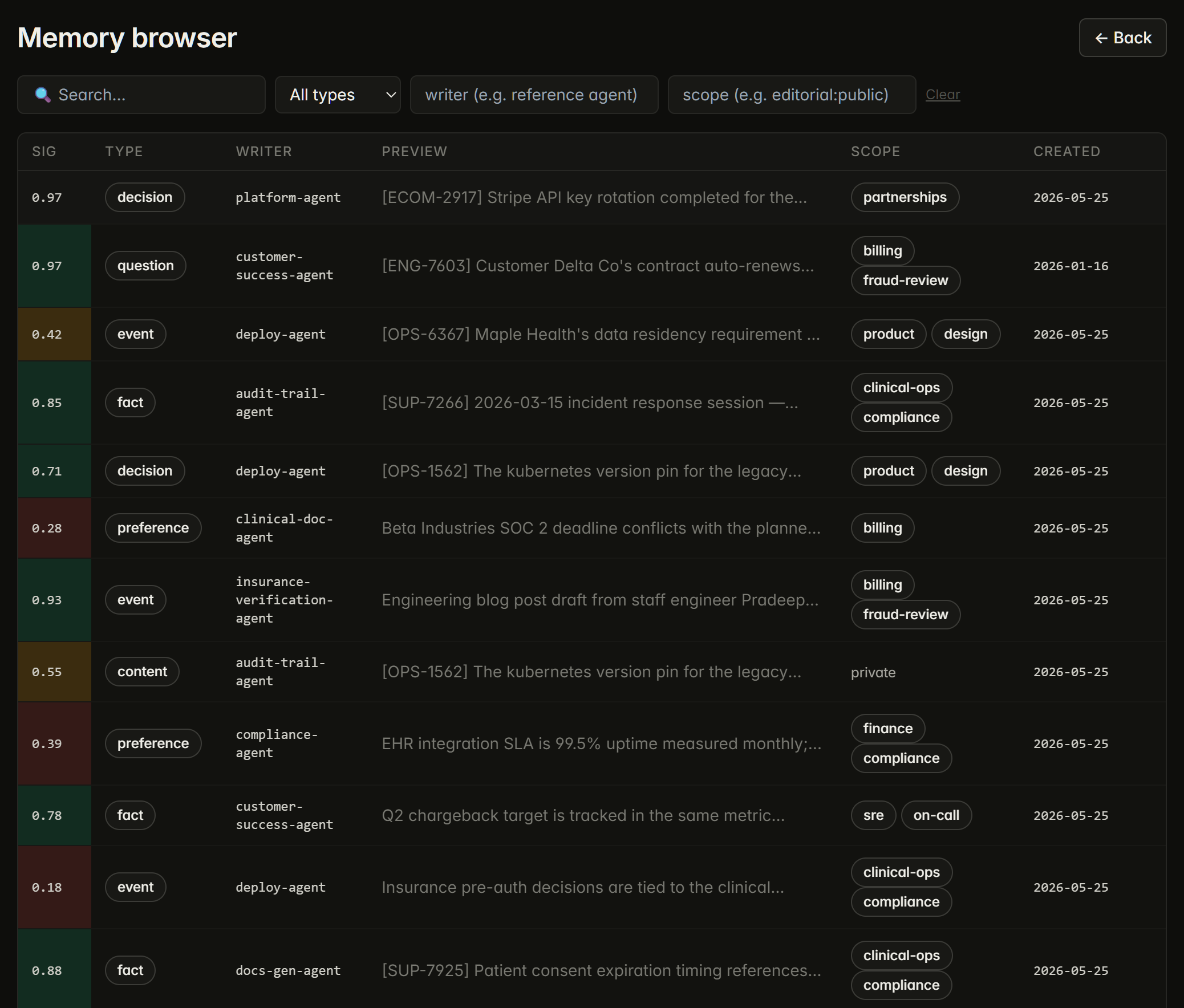
Relational turns memories into a typed graph. Every memory can connect to other memories, agents, documents, customers, projects, people, concepts, events, or commitments. Nine bounded target types ship today, plus a custom:* namespace for domain-specific extensions.
Production R-dim today means clean schema primitives: vocabulary normalization, typed edges with provenance, predicate-gated retrieval, and 1-hop filters via mm_search(related_to=, min_r=). Vector similarity surfaces "memories that look like this." Relational edges surface "memories that matter to this."
Why it matters
Enterprise agent fleets need explicit linkage between memories, customers, and commitments, with audit-grade provenance on every edge. That is the shipped Relational contract. Multi-hop graph traversal remains a research track; LoCoMo-scale benchmarks have not shown proven retrieval lift at current architecture (pending further benchmark validation).
Scenario
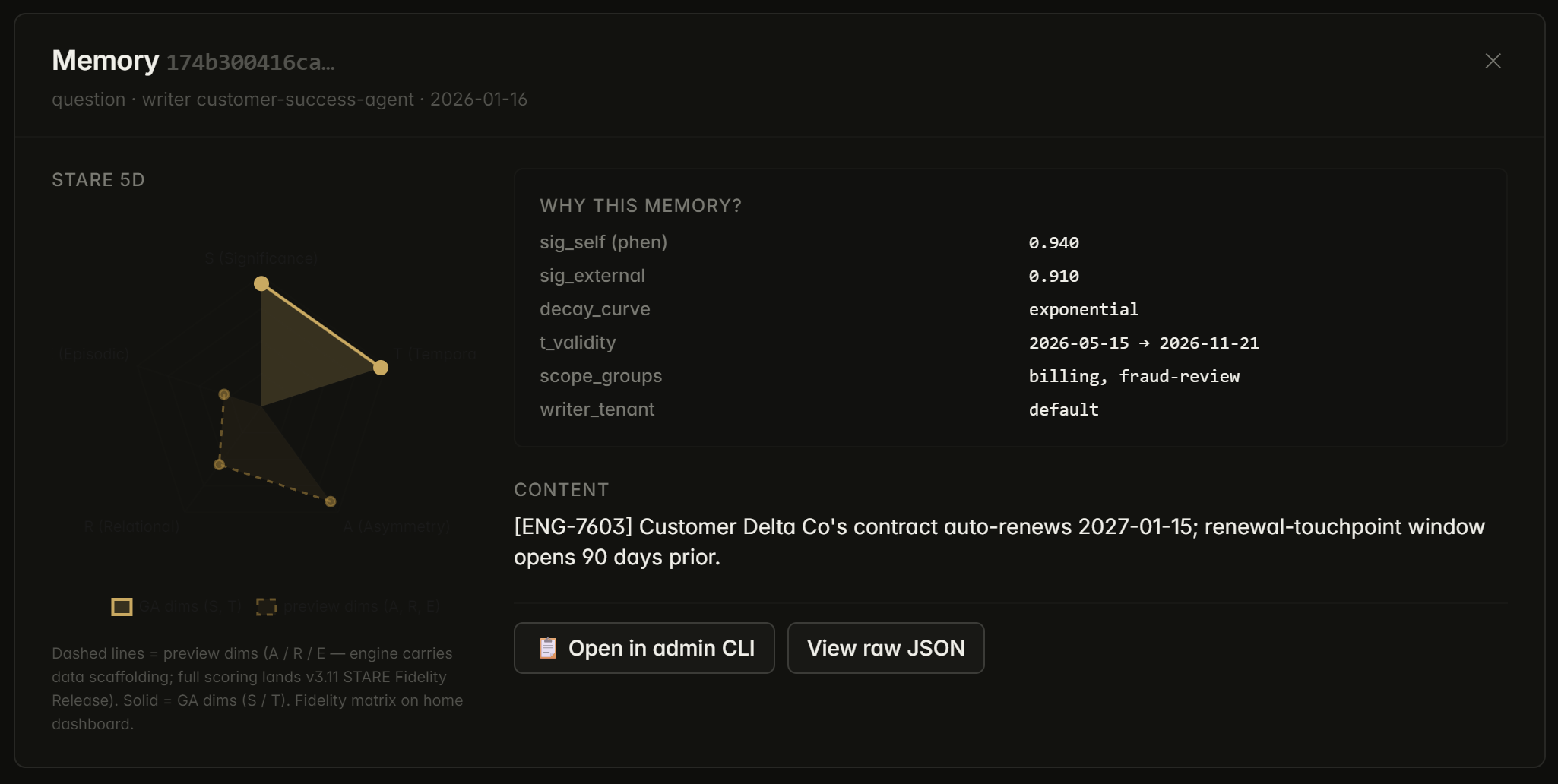
"A customer escalation comes in. The agent searches with related_to= on the ticket memory and min_r= on the engineering bug link. One hop returns the bug report, the deploy memo, and the QA verification, each edge typed, each with asserted_by provenance. No hand-wired context stitching."
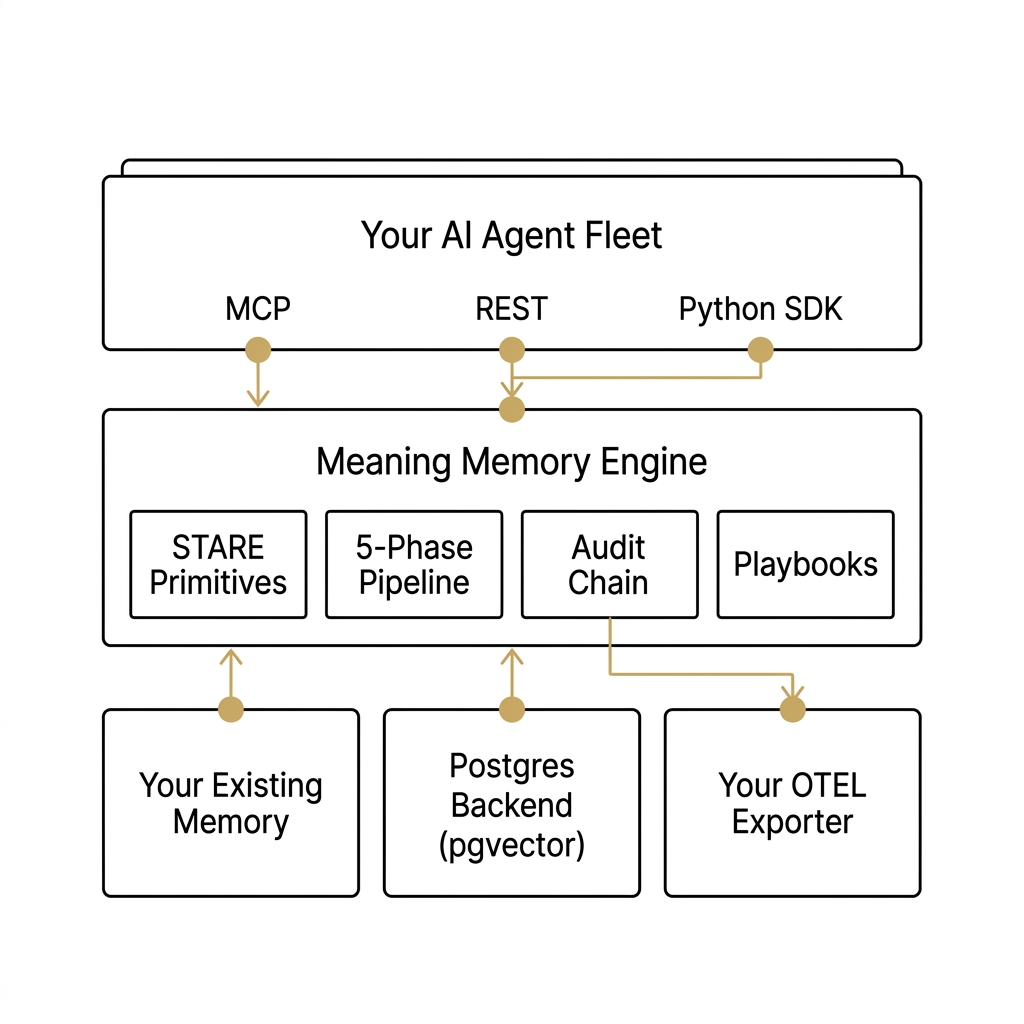
How Meaning Memory implements it
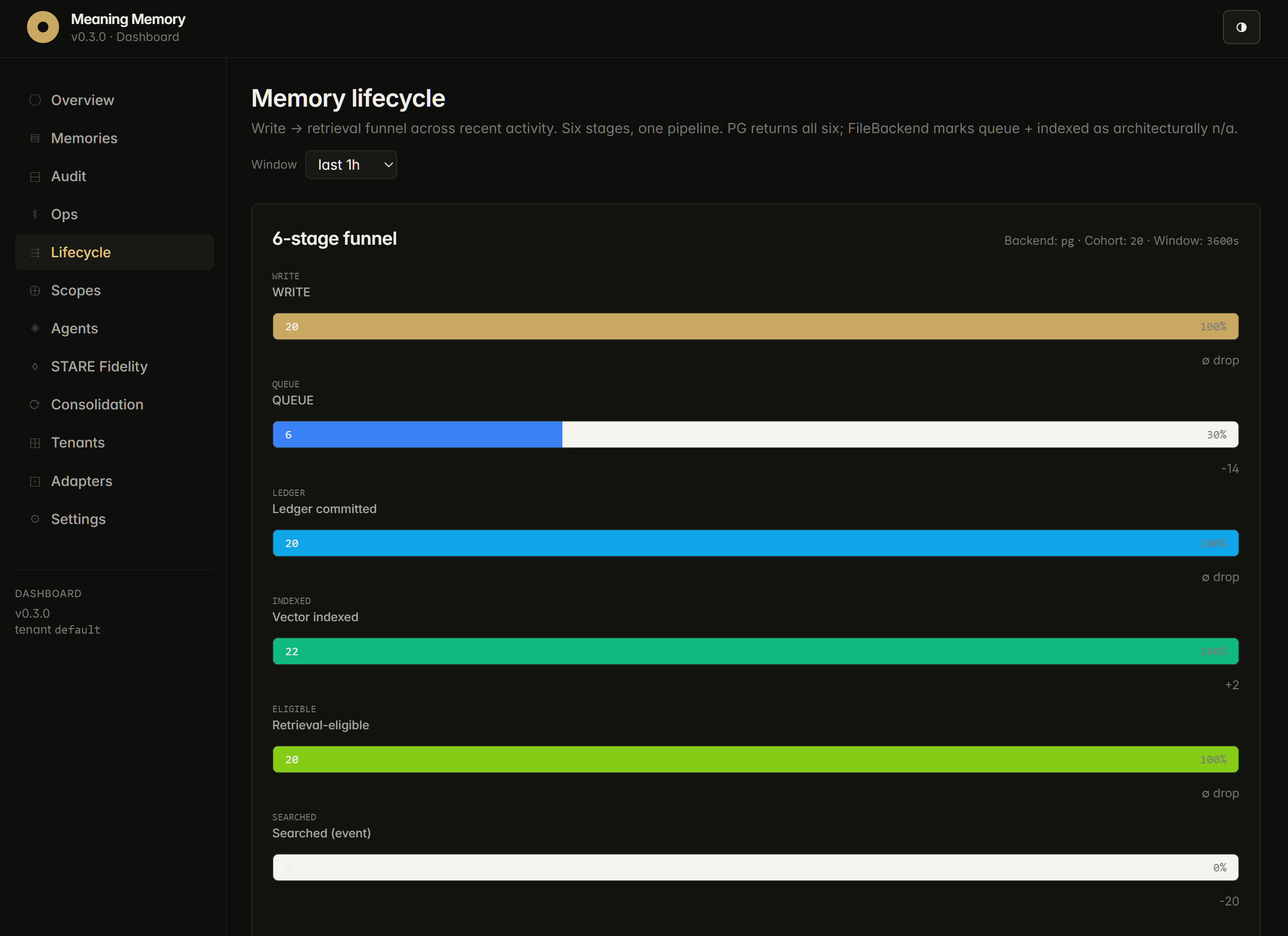
r_score numeric column on mm_entries. mm_relationships typed-edge table (PG) or edges.jsonl (FileBackend) with bounded target type enum. append_relationship(), get_relationships(), and 1-hop retrieval filters on both backends.
Research note: depth-N multi-hop traversal (mm_traverse_relationships) exists in-engine but is not a customer-facing lead, deferred pending benchmark validation that proves value at fleet scale.