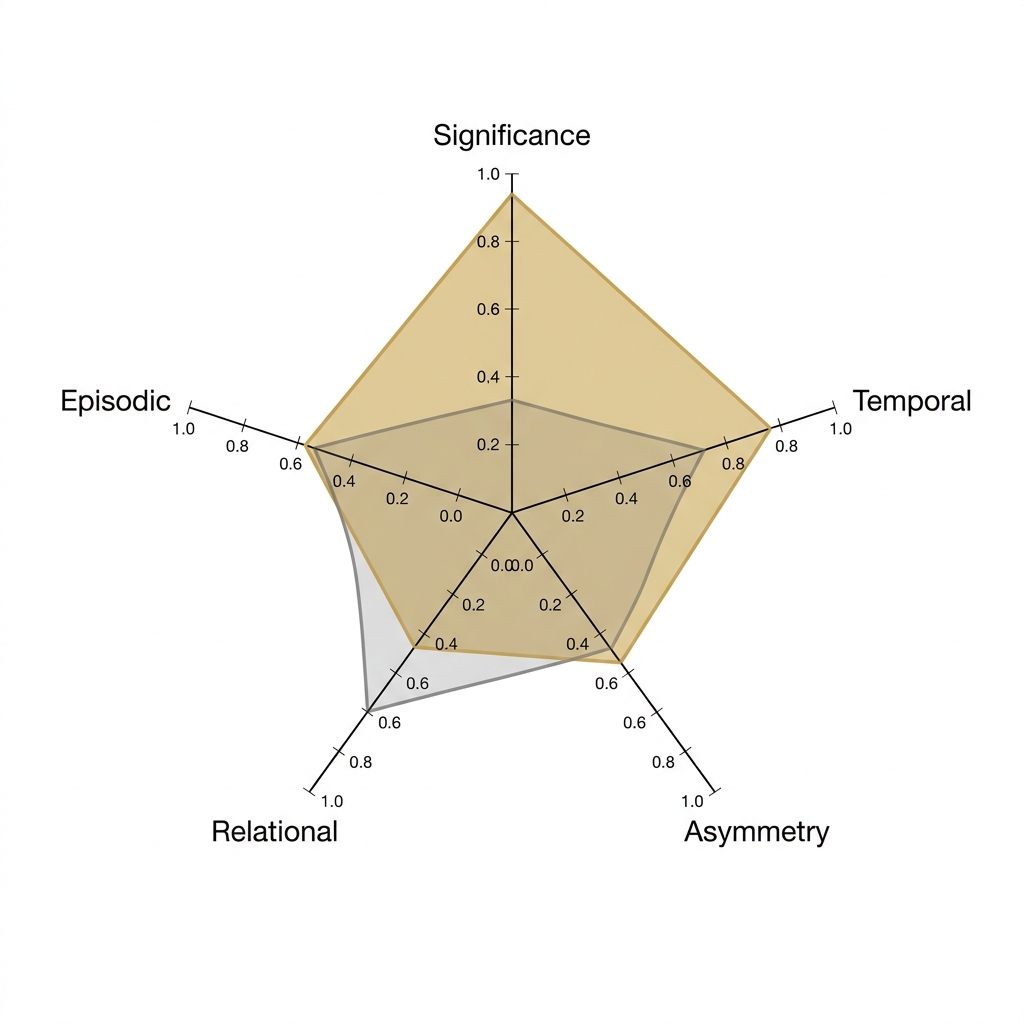
Relational turns memories into a typed graph. Every memory can connect to other memories, agents, documents, customers, projects, people, concepts, events, or commitments. Nine bounded target types ship today, plus a custom:* namespace for domain-specific extensions.
Multi-hop traversal lets agents reason across the graph: "show me everything connected to this customer ticket within two hops." Recursive CTE queries on Postgres return path-explain answers, with a configurable depth cap and a statement-level timeout so a misconfigured query can never freeze the request path.
Why it matters
Vector similarity surfaces "memories that look like this." Relational edges surface "memories that matter to this." The first is retrieval. The second is reasoning. Production agent fleets need both.
Scenario
"A customer escalation comes in. The agent calls mm_traverse_relationships(customer_id, max_depth=2) and gets back the original support ticket, the engineering bug it references, the deploy that superseded the bug fix, the QA verification memo, and the resolution debate. Five hops, one query, full path-explain via mm_explain_path."
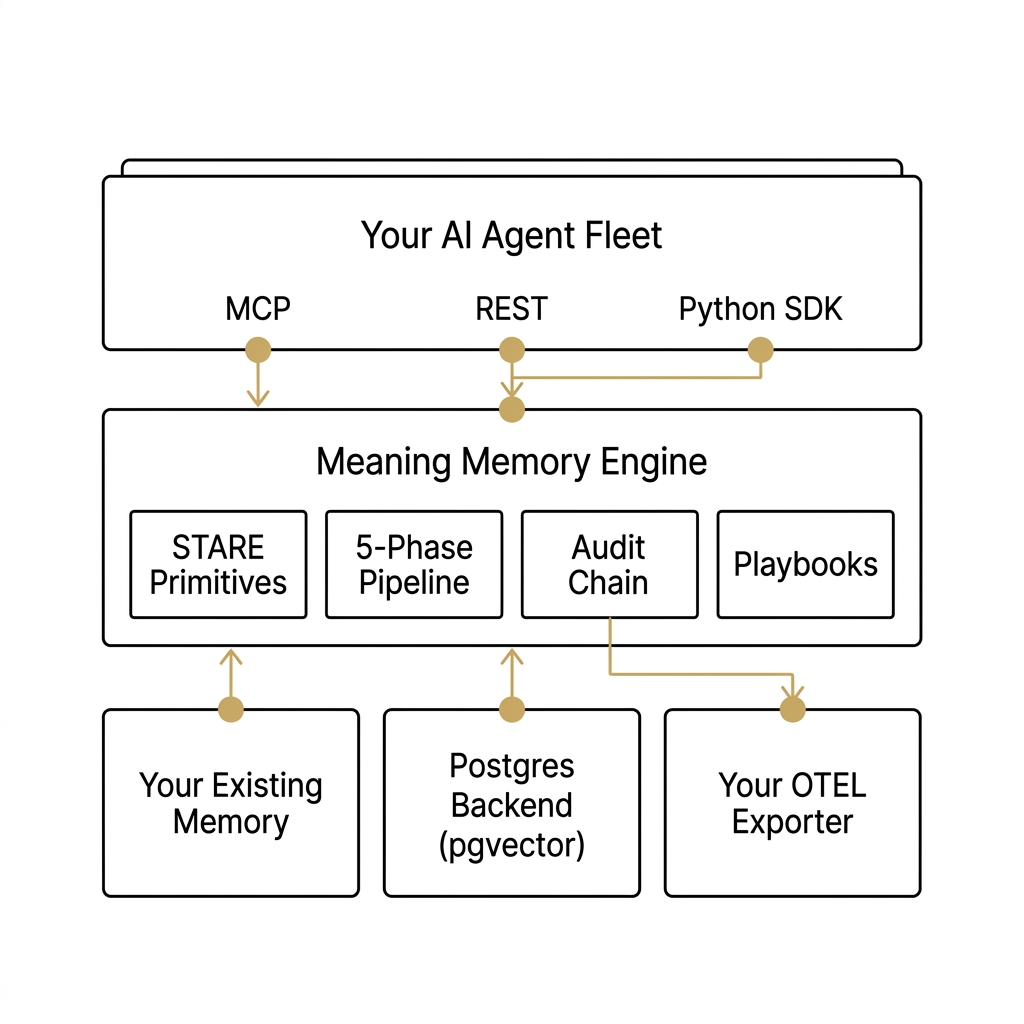
How Meaning Memory implements it
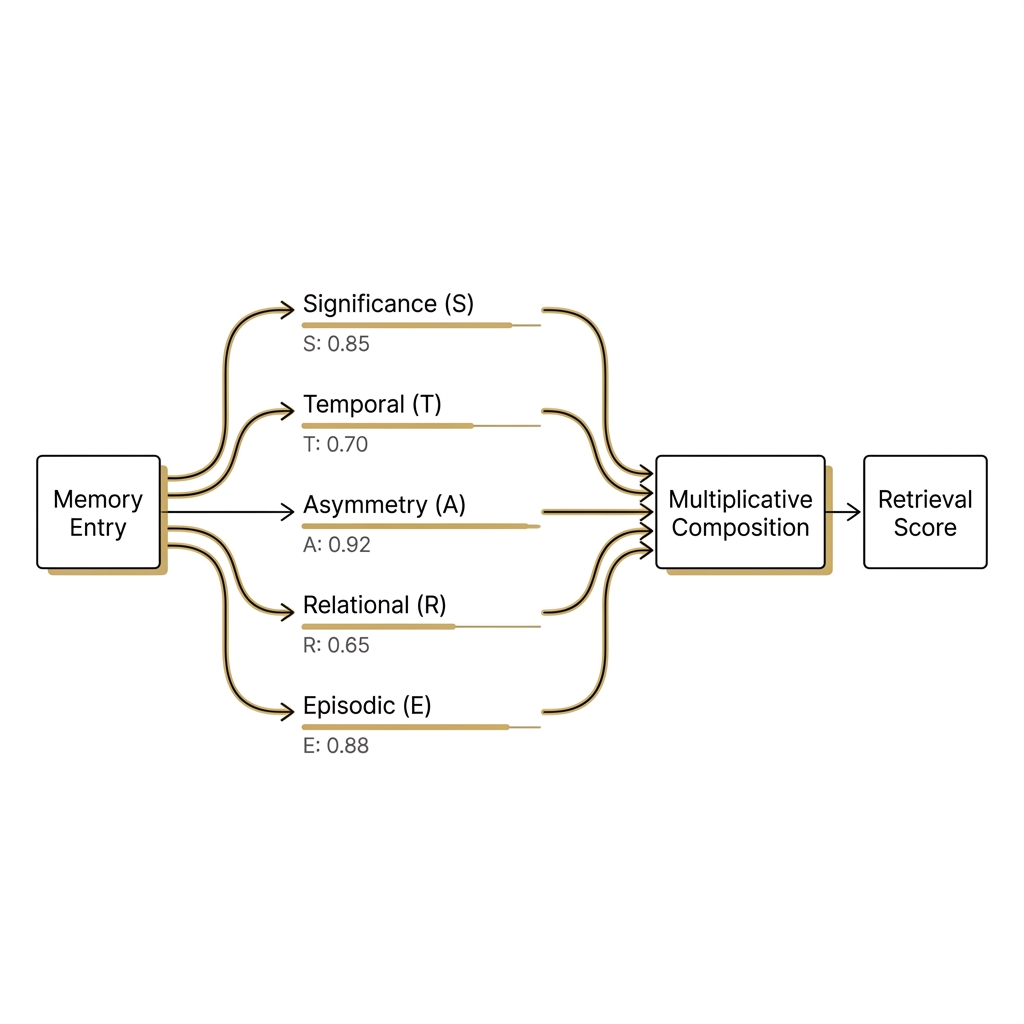
r_score numeric column on mm_entries. mm_relationships typed-edge table with bounded target type enum. mm_traverse_relationships() and mm_explain_path() MCP tools wrap the engine API.
Backend note: multi-hop traversal is Postgres-backed by architecture. FileBackend deployments (lighter, air-gapped) get scalar r_score and single-hop access today; full traversal is on the v3.11+ roadmap.